

Improve SEO by Auditing and Fixing Canonical Tags (and How to Do It)
The canonical tag was introduced in February 2009 by Google, Yahoo, and Microsoft (Bing) to address a significant SEO challenge: duplicate content within websites and across different domains.
Back in the early 2000s, as Google was solidifying its dominance, many webmasters (as they were called then) discovered they could improve their rankings simply by copying someone else’s content and reposting it on their own websites. Unsurprisingly, the original content creators weren’t happy about losing traffic and visibility that rightfully belonged to them.
Around the same time, websites were becoming increasingly dynamic. Webpages were no longer coded manually from top to bottom; instead, they were generated from database entries. This shift created a challenge for large sites, particularly eCommerce platforms, where a single product could generate multiple unique URLs based on variations like size, color, or price. As a result, search engines managed billions of redundant pages, making it harder to deliver accurate search results.
In a rare show of collaboration, the three major search engines—Google, Yahoo, and Microsoft (Bing)—joined forces to tackle the growing challenge of managing an overwhelming number of web pages. Together, they introduced the canonical tag as a solution.
I imagine their conversation going something like this:
“What if we created a tag that webmasters could place on a webpage to identify it as the primary version? It could help us avoid indexing less important variations and focus on the pages that actually matter.”
And so, the canonical tag was born. And it was great. As someone who worked on million-URL eCommerce sites, this simple tag became a game-changer. It allowed me to guide search engines toward the pages that truly mattered, cutting through the clutter of endless variations. The search engines, in turn, were pleased. They no longer had to waste time crawling and indexing unnecessary pages, which undoubtedly saved them a fortune in server resources and electricity.
How To Audit Your Canonical Tags
You’ll need a crawler like Screaming Frog or Sitebulb.
Step 1: Crawl your entire site. In this example, I’m crawling Guitar Center. Give yourself a full site crawl to get the big picture (to mimic Google). Under configurations, I typically respect noindex, but force through rel=”nofollows”.
I also don’t choose to respect canonicals because I want to capture all the duplicate content.
Export the canonical report, and you’ll get a lot of data:
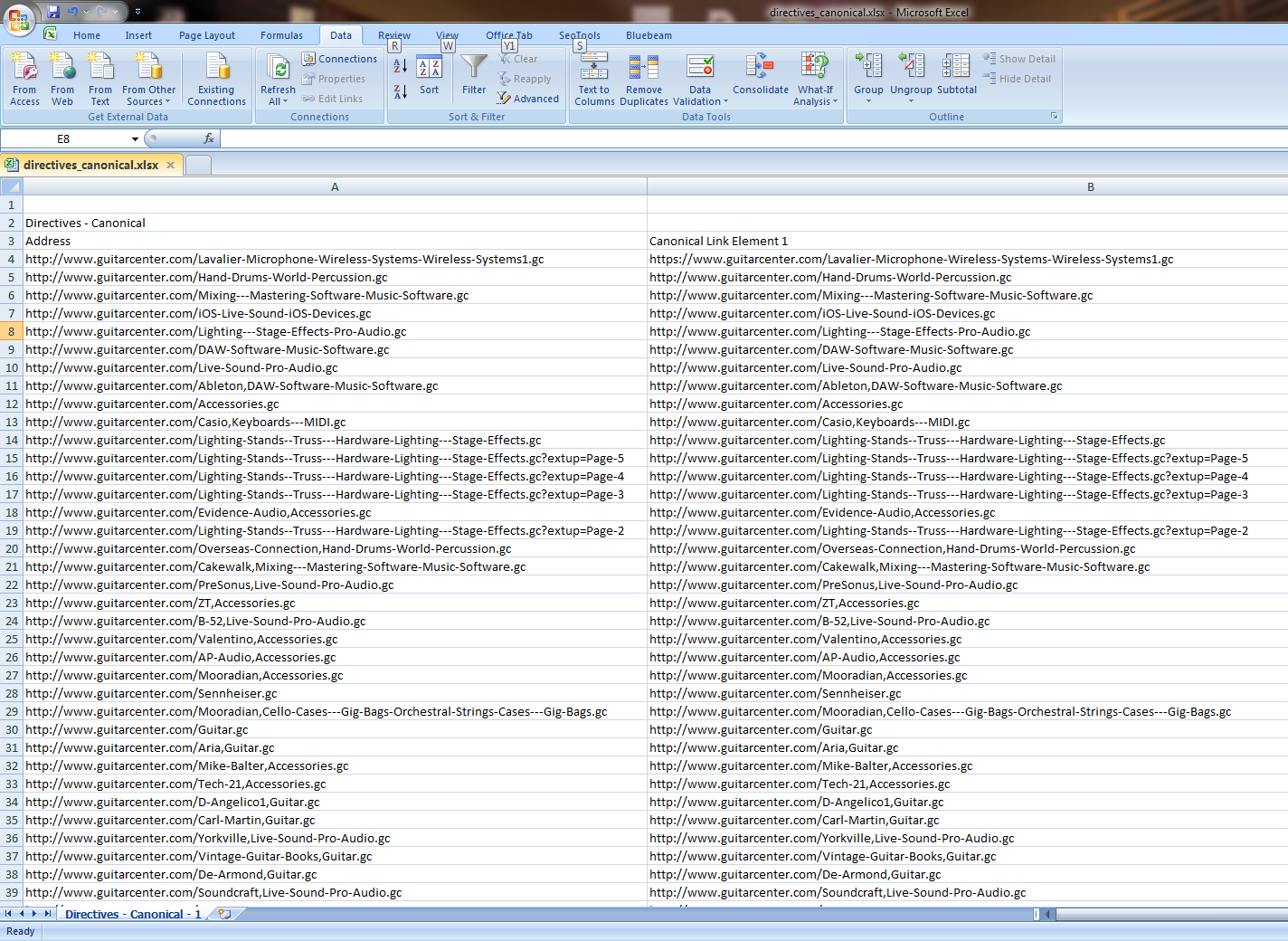
Step 2: Let’s compare column A to column B, and see where the mismatches are. The magic formula to paste into column C is:
=IF(A4=B4,"Equal","Not Equal")Next, sort to view only “Not Equal”. You’ll get something like this. These need to be fixed:
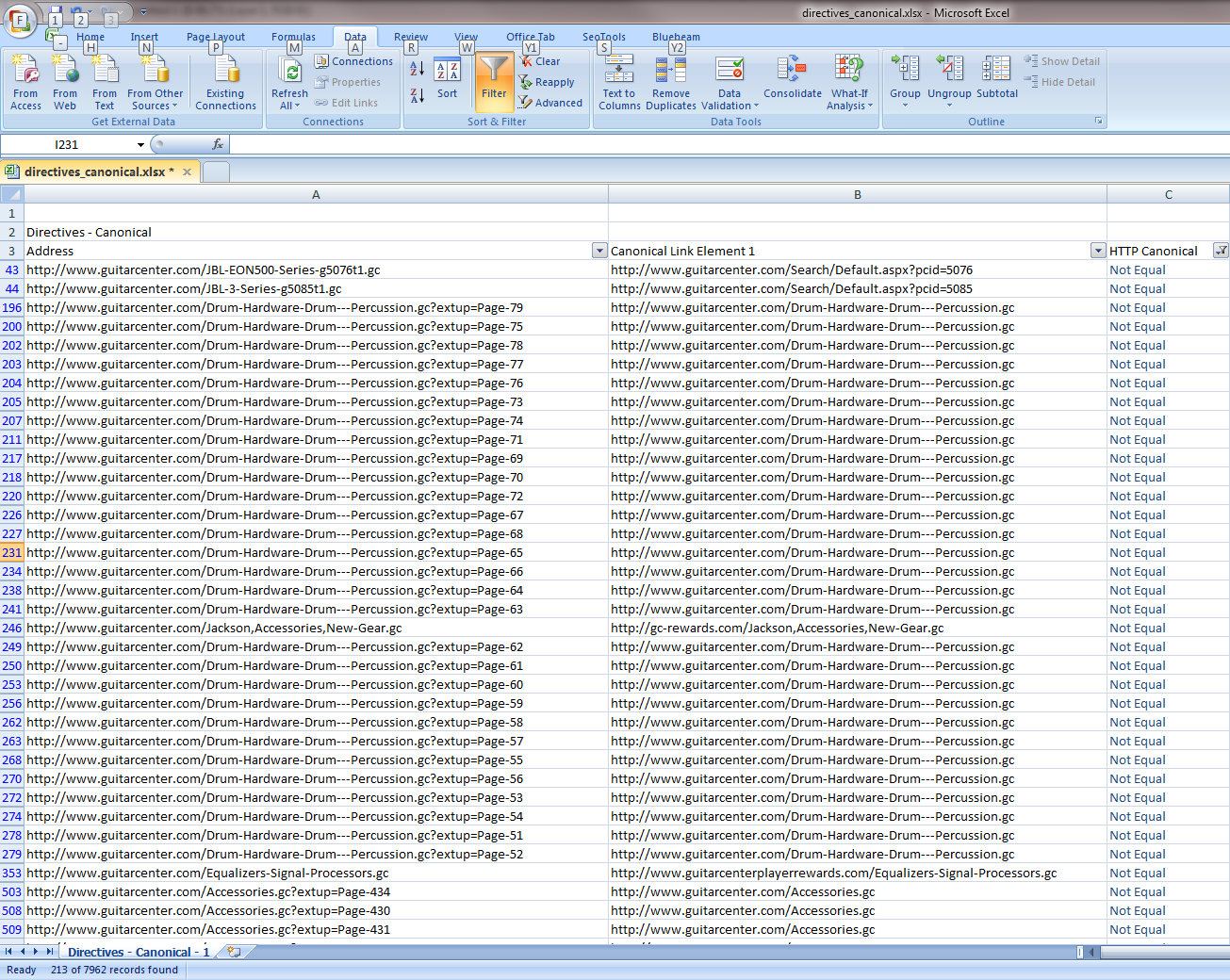
Let’s examine the first result. The spreadsheet tells us this page: https://www.guitarcenter.com/JBL-EON500-Series-g5076t1.gc has a canonical tag for this page: https://www.guitarcenter.com/Search/Default.aspx?pcid=5076.
So in other words, the webpage is telling Google not to index this page:
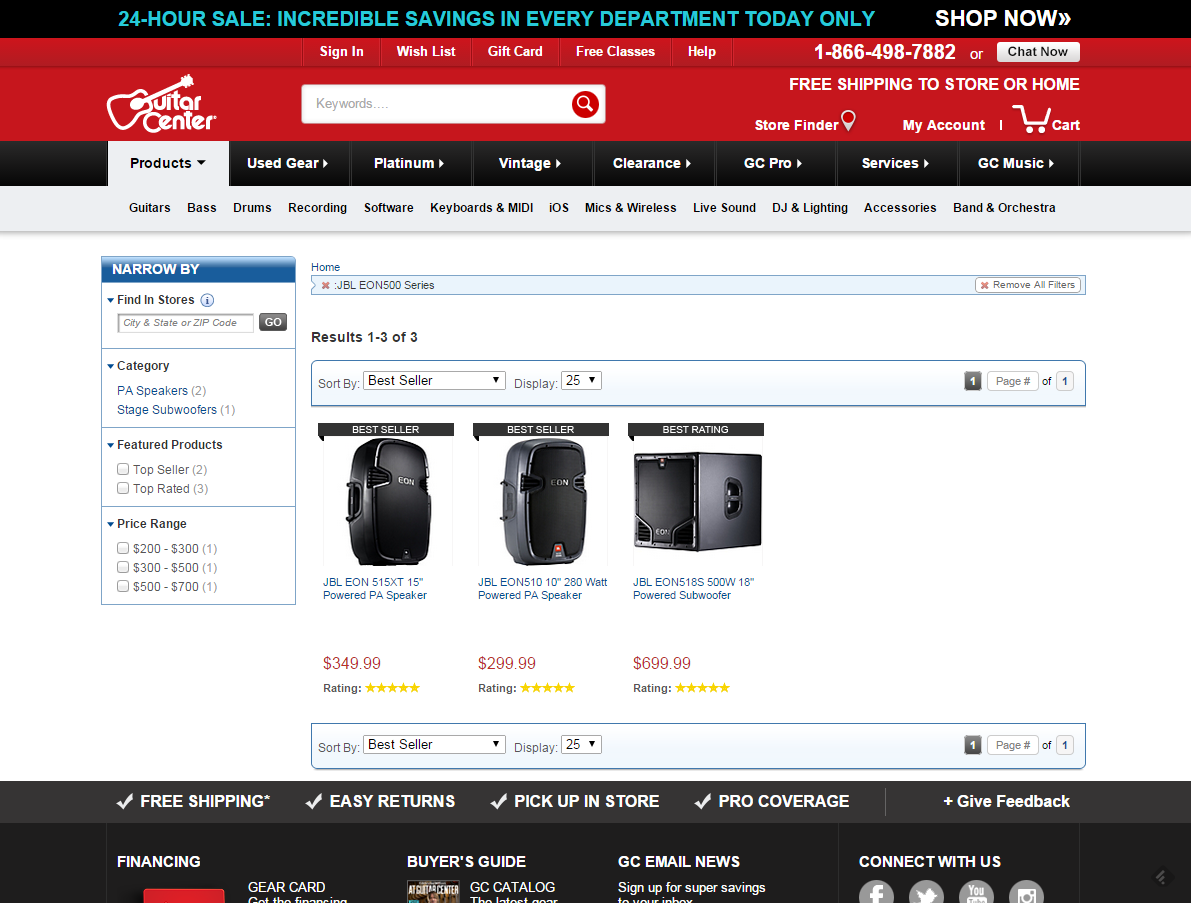
But the canonical tag says they should instead index this page, an apparent mistake and bad canonical tag implementation (hey Guitar Center, call us!):

It would be problematic if Google decided to follow the canonical tag in this instance. To verify this, I checked whether https://www.guitarcenter.com/JBL-EON500-Series-g5076t1.gc was indexed — and it wasn’t. Unless there’s a bigger issue I’m unaware of, this seems to be a case of a flawed canonical tag implementation.
As mentioned throughout this article, Google reserves the right to ignore your canonical tag when they believe it’s in the best interest of search users. However, there are specific scenarios where Google is more likely to disregard your tag. These include:
- Canonicalising to the wrong URL. (This has been mentioned.)
- Broken canonical URL. (If the code is wrong, Google is not very forgiving.)
- Canonical loop. (If the canonical tags send Google in a loop, they’ll disregard the tag.)
Canonical Tag vs 301 Redirect
A quick, relevant tip: I always advise clients to use 301 redirects instead of relying solely on canonical tags. While Google claims that canonical tags pass the same amount of PageRank as a 301 redirect, I believe redirects are the more reliable and preferred SEO solution. Canonical tags work best as safety nets for websites where implementing redirects is difficult, but when given a choice, a 301 redirect is always the safer move.
Identifying canonical tag outliers is relatively easy if you know what to look for. If you have any questions or want to dive deeper into canonical tag best practices, feel free contact us.
Like Technical SEO? You May Also Like:





