

Understanding Index Bloat in SEO and Crawl Budget SEO Issues
| Understanding index bloat and crawl budget is a key aspect of Technical SEO. This article will break down these concepts to help you optimize your site’s performance. At Greenlane, we specialize in Technical SEO and are here to help. If you’re facing challenges in this area, feel free to contact our team. |
TL;DR
- Too many low-value pages = index bloat. These unnecessary pages can dilute authority, cause keyword cannibalization, and confuse Google about what to rank.
- Crawl budget is limited. Google doesn’t crawl or index everything — wasting crawl budget on junk pages slows down the indexing of your important content.
- Clean up your site architecture. Use internal linking, canonical tags, noindex, and XML sitemaps to guide Google toward the pages that actually matter.
Let’s start with some definitions.
What Is Index Bloat?
Index bloat happens when a website has too many low-value or unnecessary pages indexed by search engines. These are pages that don’t support your goals or provide value to users. Common culprits include duplicate content or near-identical pages that aren’t properly managed.
Why Is It Important to Reduce Index Bloat?
Index bloat doesn’t just clutter up search engine results with unnecessary pages — it can also confuse Google about which page to rank. When multiple similar or low-value pages are indexed, they can compete with your important pages for the same keywords.
The result? Cannibalization, diluted authority, and a drop in rankings and traffic for the page that actually matters.
What Is Crawl Budget in SEO?
Crawl budget in SEO refers to the number of pages a search engine is willing and able to crawl (or discover) on a website within a given timeframe. It is commonly believed that three main factors influence it:
- Crawl Rate Limit – The maximum number of requests a search engine will make to a site without overloading the server.
- Crawl Demand – How much Google wants to crawl a site, based on factors like content freshness, authority, and overall site quality.
- Site Quality – Site quality plays a crucial role in Google’s crawling and indexing decisions, as well-maintained, authoritative sites with valuable content are crawled more frequently and efficiently.
Optimizing crawl budget ensures that search engines focus on indexing important pages rather than wasting resources on low-value or duplicate content.
Take Google, for example. It has limited bandwidth and memory allocated to each website. When a site is over-indexed, search engines like Google must waste resources processing and filtering irrelevant or duplicate pages. This can slow down the indexing of new content and negatively impact search performance. Wasting Google’s crawl resources indirectly correlates with lower organic rankings.
It’s About Helping Search Engines With Efficient Page Discovery
Managing how search engines discover pages can be challenging. Here are key points to keep in mind:
- Search engines do not index every page they crawl
- Search engines do not crawl every page they know about from previous discoveries
- Search engines (notably Google) may guess at pages that are not even crawlable
#1 and #3 above represent some energy (or budget) spent on your webpages. This is spent energy we want to better control as SEOs.
Our job as technical SEOs is to help search engines use their resources more efficiently. Better rankings often result when engines can easily identify which of your pages are most valuable to users. If you make them use more energy or they choose to focus on lesser-quality pages, there’s a greater chance they will not favor your aggregate website in ranking algorithms.
Things have changed. In the early days, Google aimed to index the entire web. However, they’ve since shifted their thinking, likely due to the sheer cost and complexity of such a massive undertaking. This means Google is now more selective about which pages it indexes. If you’re currently experiencing indexing problems, this change in approach is a possible cause.
In other words, if you’ve previously followed outdated SEO practices that encouraged indexing all your content, and those pages aren’t generating organic traffic, they might prevent other, more valuable pages from being indexed by Google.
These days, it’s wiser to be strategic about what gets indexed. Google is more selective about what it chooses to index, favoring pages with clear value, strong signals, and high engagement. Focus on getting your transactional and informational pages indexed. Don’t index tons of paginated pages, processing files, or duplicate pages. I’ve found that database-driven sites (like news and e-commerce) are the worst offenders regarding index bloat.
How To Monitor Index Bloat
Google Search Console is the best place to monitor your indexation. Here is an example of Greenlane’s indexed pages report.
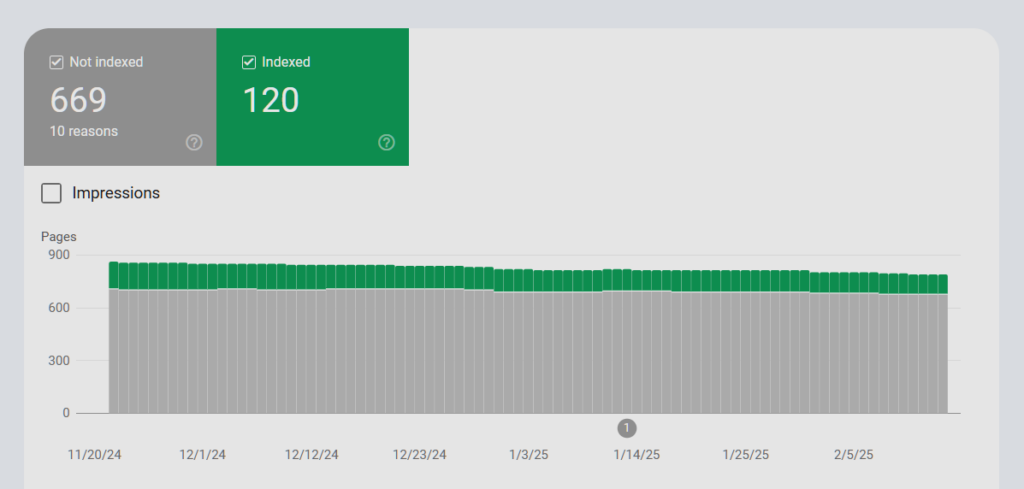
We have a smaller site, and 120 pages indexed match my expectations. This represents our lead generation pages (such as services and case studies) and our informational pages (such as articles).
However, this screenshot highlights a related issue — 669 pages are on Google’s radar but remain unindexed.
Given our site’s long history, many pages (including 404s, redirects, externally linked pages, and other unnecessary URLs made from our WordPress instance) shouldn’t be indexed. Google is handling these pages correctly by not indexing them, but they still consume crawl resources unnecessarily, which means this site has a Crawl Bloat problem.
This means Google has already expended resources crawling these unimportant pages, effectively wasting our crawl budget. In my view, this qualifies as bloat. I need to provide Google with clearer signals about what truly matters and discourage them from wasting resources on junk pages.
I have some SEO to do. I won’t be able to get this number to zero, but the goal is to get as close as possible.
How To Manage Index Bloat
If we want Google to focus only on essential pages, we need to examine our website’s internal architecture. This includes navigation, internal linking, XML sitemaps, and links from outside web pages. Managing bloat is just one phase of a diagnostic system; see our full breakdown of what a real SEO audit includes to see how this fits into a recovery plan.
Site Architecture & Internal Linking
Ensuring navigation, internal linking, XML sitemaps, and external links prioritize important pages is key. Internal links should flow toward indexable pages, reinforcing their importance.
Canonical Tags
Proper canonicalization helps consolidate duplicate content and prevents unnecessary crawling of redundant pages. However, it’s important to note that canonical tags are a suggestion, not a directive—Google may still crawl & index duplicate pages.
Redirect Management
Minimizing redirect chains and ensuring clean click paths can improve crawl efficiency. Google follows redirects, but reducing unnecessary ones prevents wasted crawl budget. While single redirects are generally fine, multiple redirects in a row (redirect chains) waste crawl budget and slow down page discovery.
Noindex for Unwanted Pages
A meta robots noindex tag is the best way to keep pages out of the index while allowing Google to crawl them. Is the code crawl wasting crawl budget? There’s debate in the SEO community about whether Google fully respects crawl budget limits when crawling noindexed pages. While noindex prevents indexing, it does not always stop crawling.
Robots.txt for Blocking Crawls
If noindex isn’t possible, a robots.txt block can prevent crawling, but does not remove pages already indexed. If a page blocked by robots.txt is found via links, it can still be indexed.
Nofollow on Links
While nofollow is now treated as a hint, it can still reduce unnecessary crawling. It’s useful when linking to low-value or irrelevant pages. Internal nofollow should be used strategically—overusing it can prevent important pages from receiving link equity.
Organized XML Sitemap
An organized XML sitemap helps search engines efficiently discover and prioritize important pages, ensuring that essential content is crawled and indexed more effectively. Ensure only high-value pages are included in your XML sitemap to guide search engines efficiently.
Managing index bloat and optimizing crawl budget are essential for ensuring that search engines focus on the pages that matter most. By refining your site’s architecture, implementing smart internal linking, and using directives like noindex, robots.txt, and canonical tags effectively, you can improve indexing efficiency and search performance. SEO is an ongoing process, and staying proactive with technical optimizations will help your site remain competitive. If you need expert guidance in fine-tuning your crawl efficiency, Greenlane is here to help—reach out to our team anytime.





