

How to Find Old Redirect Opportunities & Reclaim Links (with the Wayback Machine)
Necessity is the mother of invention. Many years ago, one of our clients bought a popular, content-rich website and redirected it to their current domain. SEO (and retaining the backlinks) were not on their radar at that time. Upon learning about the migration, we asked if they had redirected the site at a page-level or just redirected the site to their own homepage. The client had no idea how the redirection was done and they didn’t have a redirect list (list of the old, legacy URLs) to work from. We needed to invent a plan to gather up the data.
We needed data, and that required knowing about the pages that used to exist on the old domain. First, we began by crawling the WayBack Machine with Screaming Frog to get a deep list of the site’s URLs before it had been purchased and its URLs redirected. Next, it was a simple task of scraping the URLs from the WayBack Machine and running them through Screaming Frog in list mode to see where they had been redirected. What we found was that the only page that had been correctly redirected was the homepage. In fact, every page had been redirected to the homepage (d’oh!). Link relevancy matters, so we wanted to fix this.
Needless to say we always recommend creating a redirect list if you’re in the process of redirecting a site or moving domains, but just in case you made the same mistake as our client, here’s our process step-by-step so that you can use Screaming Frog and the WayBack Machine to find and fix misdirected links, too.
Step 1: Configure Your Spider Correctly
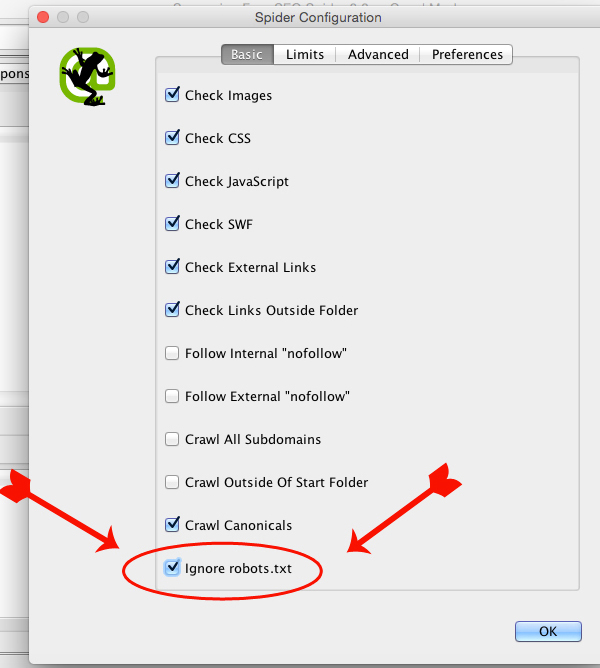
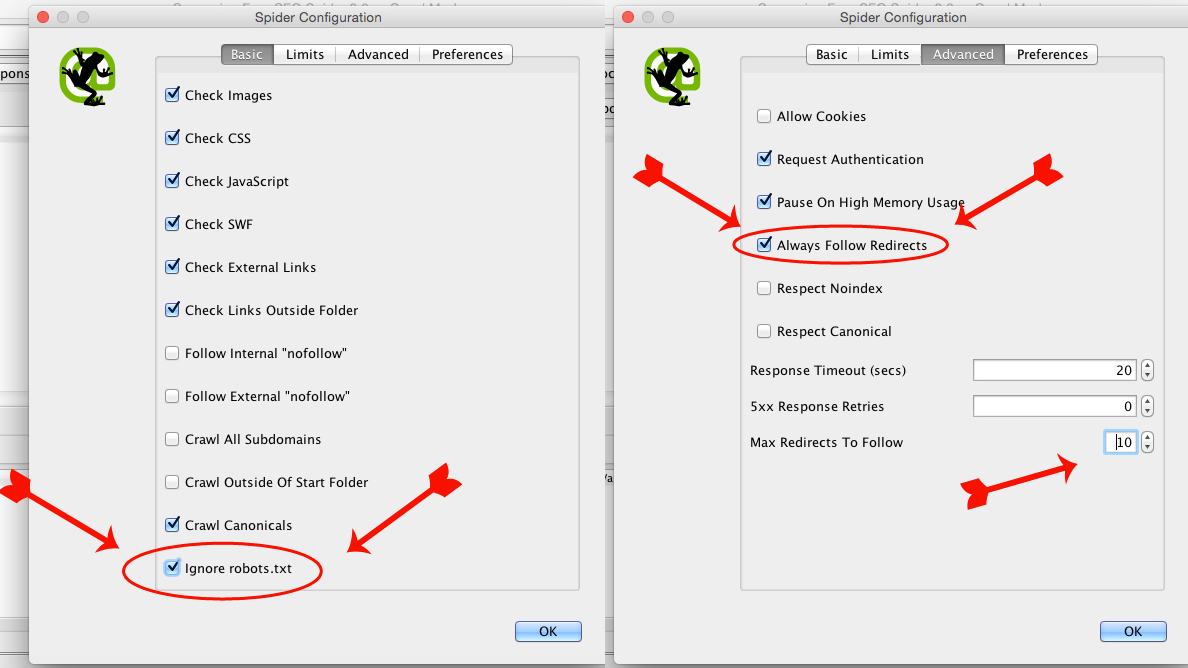
First things first. Open up Screaming Frog, select ‘configuration’ and click on ‘spider’. Under the basic spider settings make sure the “ignore robots.txt” box is selected. This directive is for the WayBack Machine to tell spiders – notably search engines – not to crawl its archived pages, so naturally we want to ignore that.
Step 2: Gather Up a Good Sample of Snapshot URLs
Before going any further, it’s important to get a high-level view of the site in question and its URLs before any work was done. To do this, enter the domain in question into the WayBack Machine (for the sake of this exercise we’ll use Godiva because hey, who can resist chocolate? Not me!). The resulting image will look something like this:
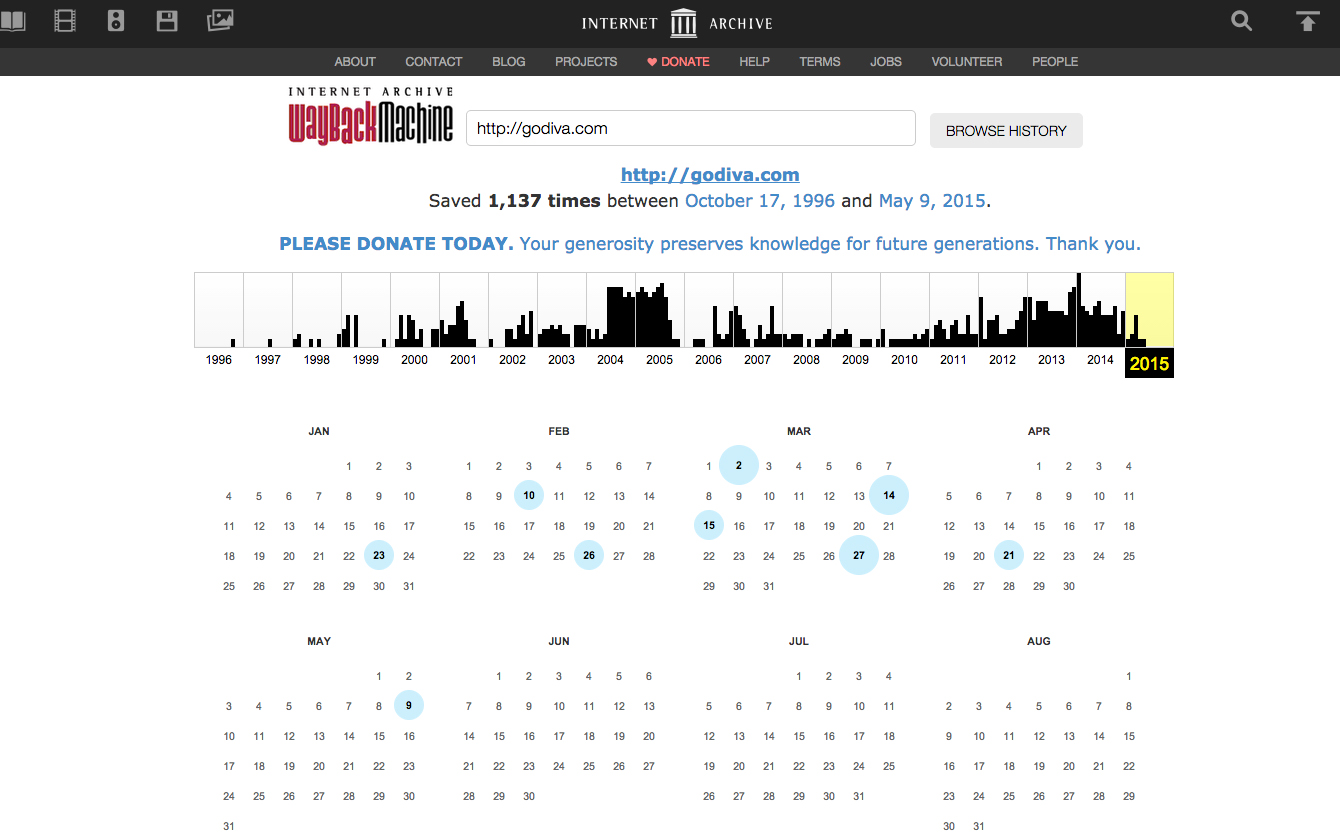
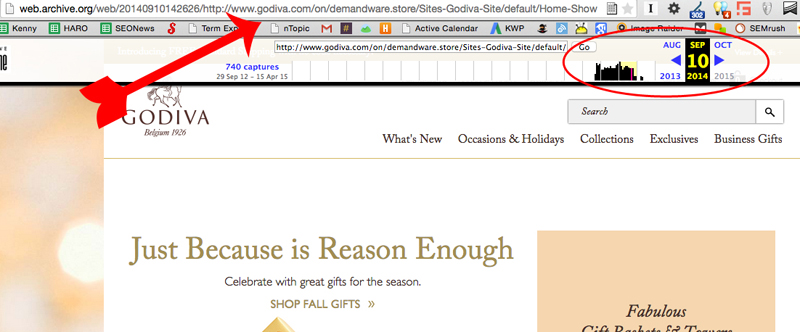
You’re going to select several URLs throughout the lifetime of the domain to use as a baseline. Do this by clicking on one of the data chunks shown at the top of the timeline, then click one of the days circled in blue in the calendar below to be taken to a snapshot of the domain at that date in time. (For the sake of our exercise we’re only going as far back as 2008.) The URL you’ll want to pay attention to is the one in your search bar. We’ll call it the snapshot URL.
Repeat this step, collecting snapshot URLs from different dates on the domain’s WayBack Machine timeline until you’ve got an adequate sample size.
Pro Tip: “But Kali, how many snapshot URLs constitutes an adequate sample size? 10? 20? 5?” Good question. It depends on the site you’re assessing – how old the site is, how frequently it’s been updated, etc. This number can vary greatly from site to site. For this example we grabbed about a dozen snapshot URLs.
Step 3: Go WayBack & Get Your Crawl On
Plug one of the snapshot URLs you just found in Step 2 into Screaming Frog, hit “Start” and relax for a second. After the crawl is finished, click the “Filter” dropdown and select HTML to view a list of all the various URLs that existed at that moment in time. That’s right – Screaming Frog just plugged paths from the navigations and internal links. Click “Export” to save the list of URLs.
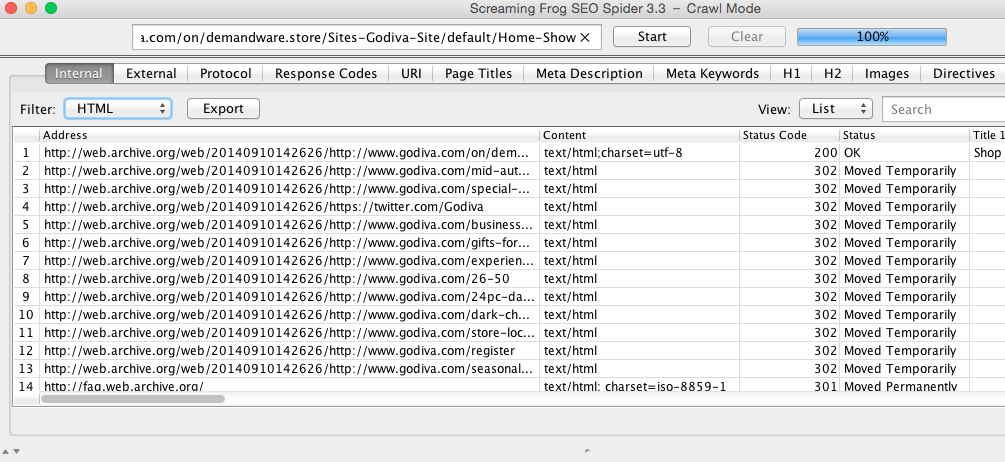
Rinse and repeat, running each snapshot URL through Screaming Frog one at a time, exporting each report as you go until you’re out of snapshot URLs. When you’re finished, combine the exports into one workbook. What you’ve got now is what we ended up with – a redirect list of legacy URLs from our client’s (Godiva in this example) old domain.
Step 4: Decipher the Codes or How to Kill Two Birds With One Stone
Now, it’s just a matter of finding out where the heck all the URLs were redirected to! Time to run Screaming Frog in list mode. Select Mode, and List. Make sure your spider’s settings are still set to ignore robots.txt. Under the advanced settings, select the “always follow redirects” box. This directive tells the spider to keep crawling the URL for up to 10 redirects (we chose 10, you can choose as many as you want).
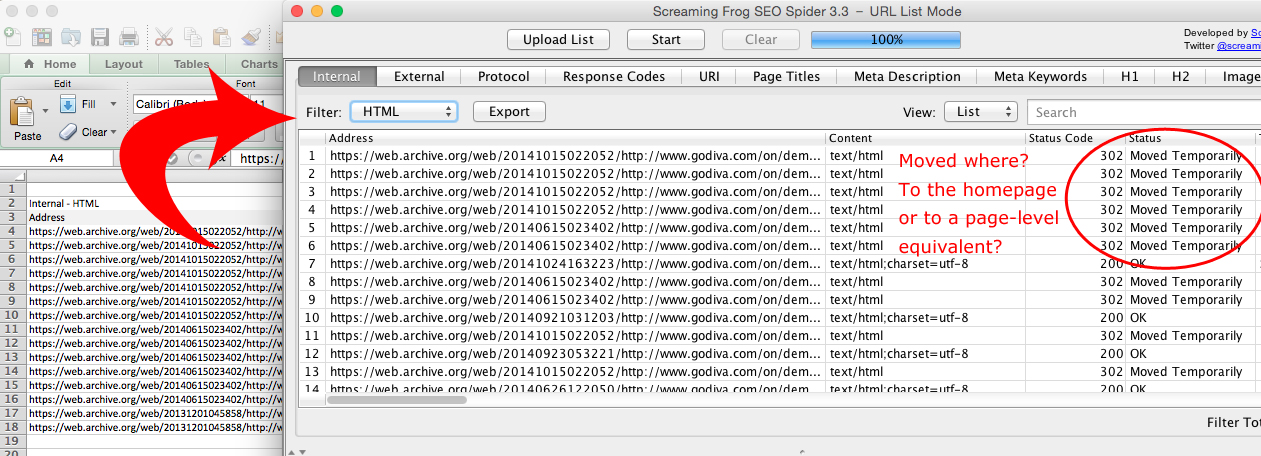
Now copy and paste the list of legacy URLs from your workbook into Screaming Frog (or you can upload them if you’ve got a really long list), and hit Start.
Pay special attention to the URLs with 302 and 301 status codes. These are the pages that either need to be redirected to an equivalent page on the site’s new domain or to the homepage. Best SEO practices dictate using page-to-page redirects whenever possible, and redirecting to a page with similar content when 1:1 redirects aren’t possible.
Pro Tip: You’ve done Yeoman’s work using the WayBack Machine and Screaming Frog to create a redirect list from nothing. There’s just one more small step to take before handing the list of URLs off to your developer to fix: run a redirect chain report. Under “Reports,” select “redirect chains” to download the report. Not only does this make it super-easy to find and fix redirects, it makes it easy to find and fix redirect chains, too.
Summary
In our client’s case, every single URL from the old domain had been redirected to their homepage. There were also a ton of old, editorial links pointed to 404 pages. No link value or user value was being passed. In our client’s case we were dealing with the consolidation of two large, well-known sites. However, this technique can benefit smaller sites too – as long as they’re old enough to have had a major site architecture update.
We can’t overemphasize the importance of having a redirect list before migrating sites/platforms, with 404s, or even doing something as simple as changing your URL structure. That being said, if you’re stuck doing “reactive” redirection work with no redirect list to work from, you can still use this post, the WayBack Machine and Screaming Frog to get the job done. Whatever you do, just don’t do a blanket redirect of all an old site’s pages to a new site’s homepage.

More Sources for Learning About Redirection:
- Google’s official stance on 301 redirects
- W3’s Status Code definitions
- Our friends at Moz do a good overview of redirection





