

Optimize NOW For Entities and Relationships
I remember a few years ago blowing the mind of a boss with a theory that Google would eventually rank (in part) based on their own internal understanding of your object. If Wikipedia could know so much about an object, why couldn’t Google? In the end, I was basically describing semantic search and entities, something that has already lived as a concept in the fringe of the mainstream.
In the last year, Google has shown us that they believe in the value of the semantic web and semantic search engines. With their 2010 purchase of Metaweb (which is now Freebase), and the introduction of the knowledge graph, the creation of schema, and the sudden delivery of a new algorithm called Hummingbird, Google is having one hell of a growth spurt. It’s not just rich snippets we’re talking about or results that better answer Google Now questions.
We used to say Google had an elementary school education. They understood keywords and popularity. Now it can be argued Google has graduated and is now enrolled in Silicon Valley Jr. High School. Comprehension has clearly improved. Concepts are being understood and logical associations are being made. A person/place/thing, and some details about them (as Google understands it), are starting to peek through in search results.
Yesterday was my birthday. Yesterday was also the day I became Google famous – which to an SEO geek is kind of awesome. I asked Google a couple of questions (and some non-questions), and it showed me I’m an entity (incognito and logged in):
- how old is bill sebald
- what is bill sebald’s age
- bill sebald age
- birthday of bill sebald
This produced a knowledge result (like we’ve seen a couple of times before). Details on how I got this are illustrated deeper in this post:
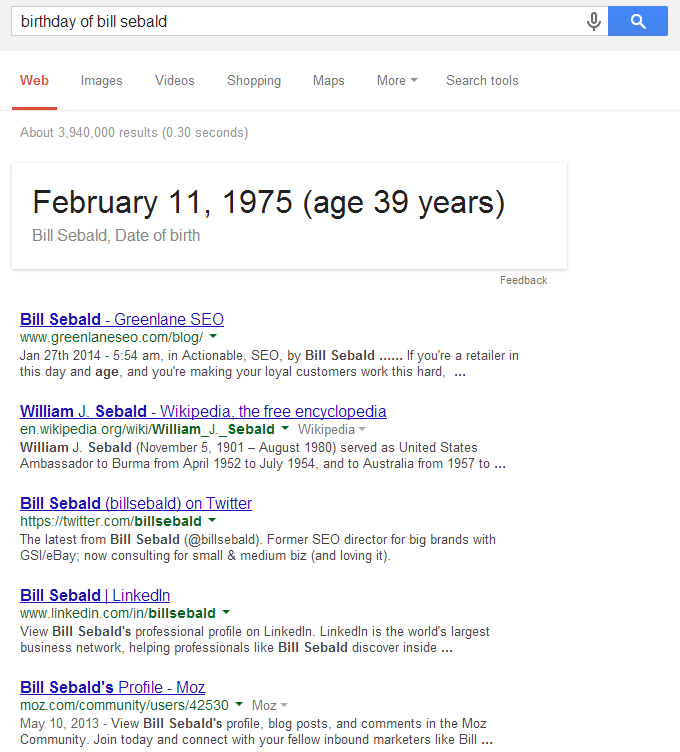
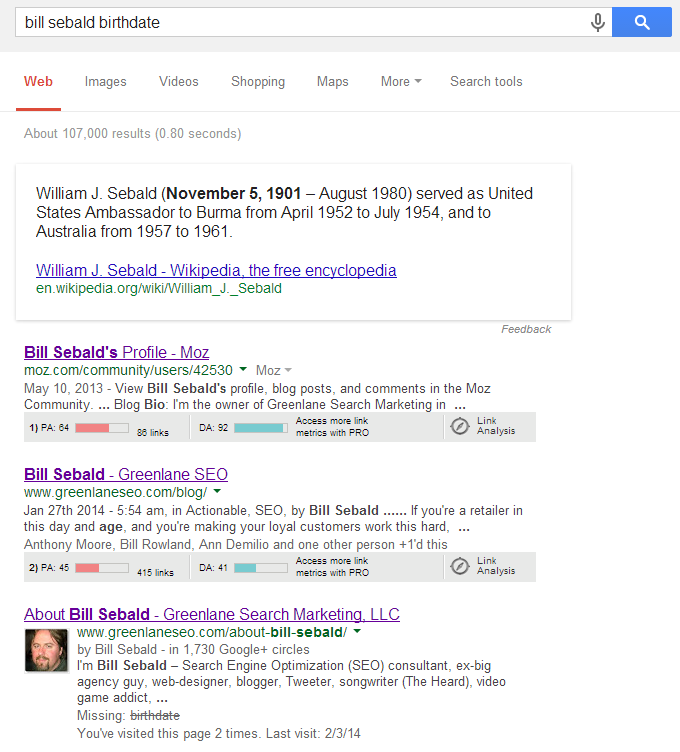
The comprehension level has its limits. Ask Google “when was bill sebald born” or “what age is bill sebald” or “when is bill sebald’s birthday,” and no such result appears. For some reason, an apostrophe throws off Google – querying “bill sebald’s age” vs. the version bulleted above, and there’s no knowledge result. Also, reverse the word order of “bill sebald age” to “age of bill sebald” and there’s no result.
Then, ask “bill sebald birthday” and you’ll get a different knowledge result apparently pulled from a Wikipedia page. This doppelganger sounds a lot more important than me.
We know Google has just begun here, but think about where this will be in a few years. At Greenlane, we’re starting entity work now. We’re teaching our clients about semantic search, and explaining why we think it’s got a great shot at being the future. Meh, maybe social signals and author rank didn’t go the way we expected (yet?), but here’s something that’s already proving out a small glimpse of “correlation equals causation.” It doesn’t cost much, it makes a lot of sense for Google’s future, and seems like a reasonable way to get around all the spam that has manipulated Google for a decade.
A new description of SEO services?
I’m not into creating a label. Semantic SEO isn’t a necessary term. You might have seen it in some recent presentations or blog post titles, but to me, this is still old-fashioned SEO simply updating to Google’s growth. This is the polar opposite to the “SEO is dead” posts we laugh at. Someone’s probably trying to trademark the “semantic SEO” label right now, or at least differentiate themselves with it. To me, as an SEO and marketer, we always cared about the intent of a searcher – semantic search brings us closer to that. We always cared about educating Google about our values, services, and products. We always wanted to teach Google about meaning (at least for those who were doing LSI work and hoping it would pay off). If this architecture becomes commonplace, it becomes part of any regular old SEO’s job duties. Forget a label – it’s just SEO.
The SEO job description doesn’t change. Only our strategies, skills, and education. We do what we always do – mature right along with the algorithms. We will optimize entities and relationships.
Where have we come from, and where are we going?
Semantic search isn’t a new concept.
I think the knowledge graph was one of the first clear indications of semantic search. Google is tipping its hand and showing some relationships it understands. Look at the cool information Google knows about Urban Outfitters. This suggests they also know and can validate this information – like CEO info, NASDAQ info, etc. Google’s not quick to post up anything they can’t verify.
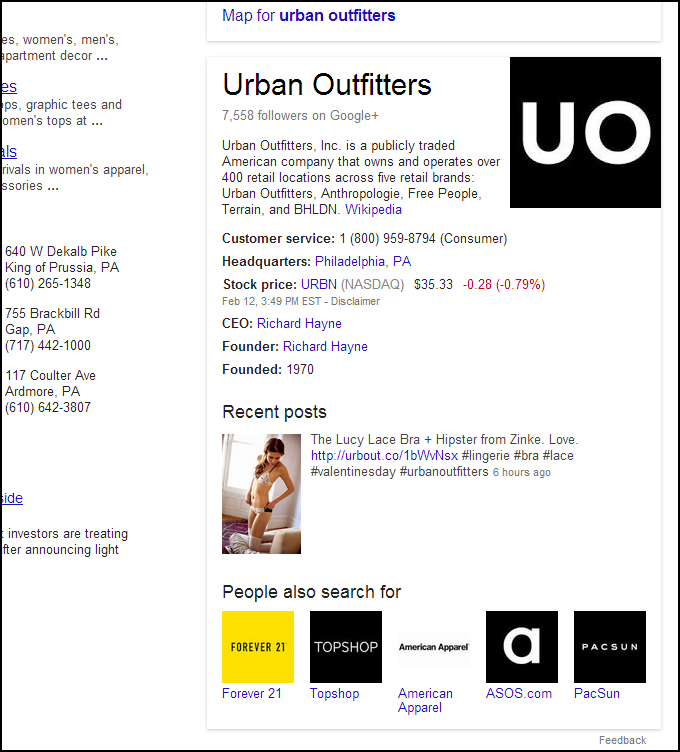
Click through some of the links (like CEO Richard Hayne) and you’ll get more validated info.
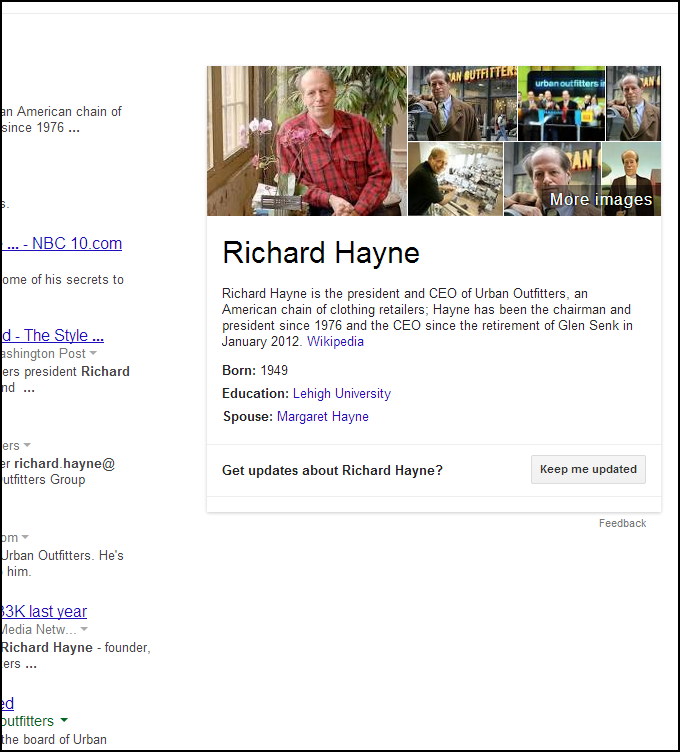
These are relationships Google believes to be true. For a semantic search to work, systems need to operate seamlessly across different information sources and media. More than just links and keywords, Google will have to care about citations, mentions, and general well-known information in all forms of display.
Freebase, as expected, uses a triple store. This is a great user-managed gathering of information and relationships. But like any human-powered database or index, bad information can get in – even with a passionate community policing the data. Thus, Google usually wants other sources. Wikipedia helps validate the information. Google+ helps validate the information.
The results I got for my age (from Google above) probably came from an entry I created for myself in Freebase. The age is likely validated by my Google+ profile where I listed my birthdate. Who knows – maybe Google also made note of a citation on Krystian Szastok’s post about Twitter SEO’s Birthdays where I’m listed there too. I’m sure my birthday is elsewhere.
But what about my height? Google knows that too, and oddly enough, I’m fairly sure the only place on the web I posted that was in Freebase:
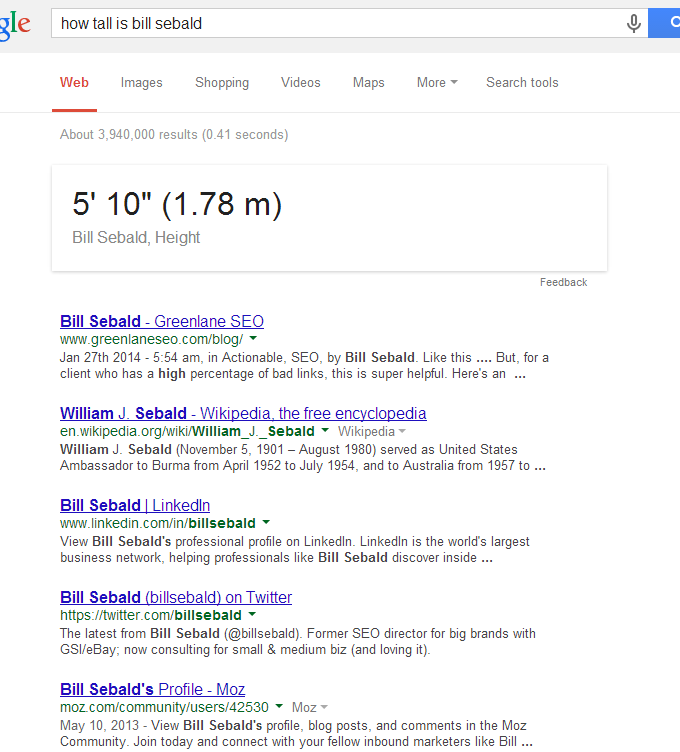
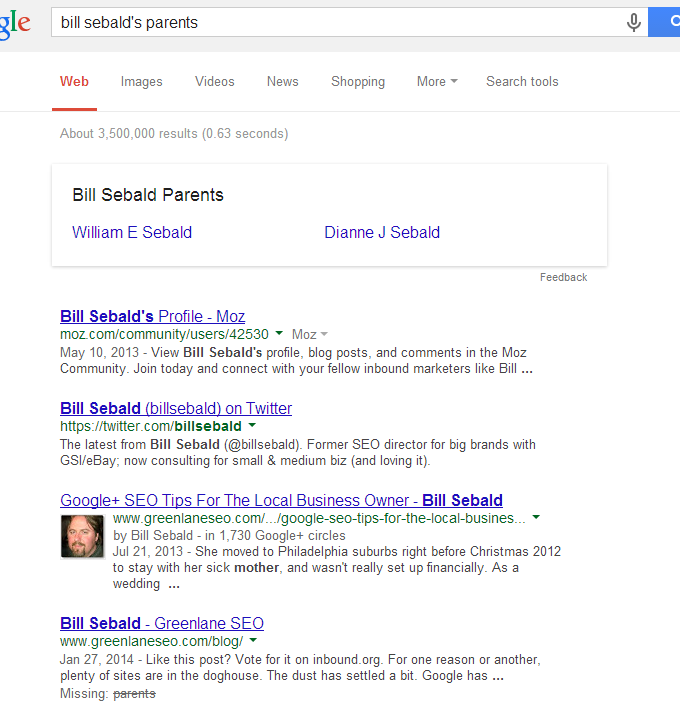
But I also added information about my band, my fiance, my brother, and sister – none of which I can seem to get a knowledge listing for. However, Google seems to have arbitrarily given one for my parents, who as far as I know are “off the grid.”
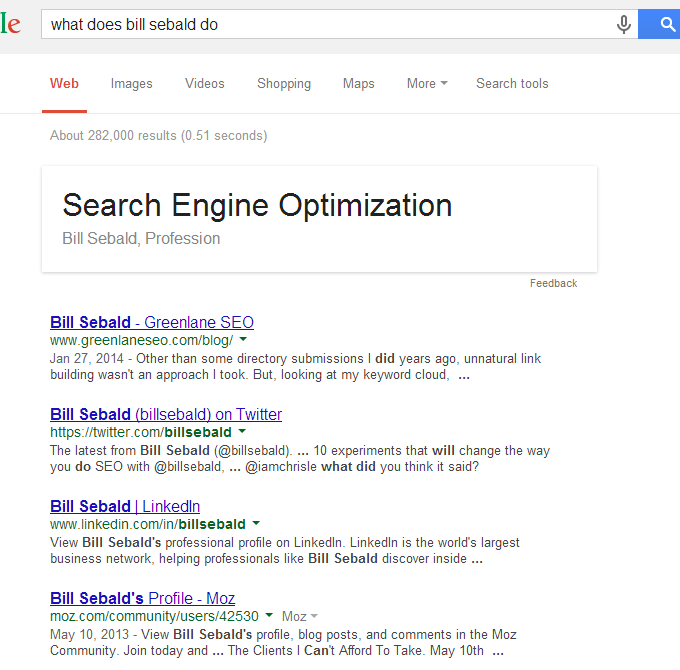
Another knowledge result came in the form of what I do for a living. This one is easy to validate (in this case only helped with several relevant links I submitted through Freebase):
This is just what Google wants to show, not all it knows
This is really an exciting part for me. When I first saw the knowledge graph in early 2013, it wasn’t just a “that’s cool – Google’s got a new display interface,” type of thing. This was my hope that my original theory may be coming true.
In fact, in a popular Moz Whiteboard, Friday from November 2012 called Prediction: Anchor Text is Weakening…And May Be Replaced by Co-Occurrence, I was hopeful again. There was a slight bit of controversy here on how a certain page was able to rank for a keyword without the traditional signs of SEO (in this case the original title mentioned co-citation, where Bill Slawski and Joshua Giardino brought some patents to light – see the post for those links). My first thought – and I can’t bring myself to rule it out – might have been that its none of the above; instead, this is Google ranking based on what it knows about relations of the topic. Maybe this is a pre-Hummingbird rollout sample? Maybe this is the future of semantic search? Certainly, companies buy patents to hold them hostage from competitors. Maybe Google was really ranking based on internal AI and known relationships?
Am I a fanboy? You bet! I think the idea of semantic search is amazing. SEO is nothing if not fuzzy, but imagine what Google could do with this knowledge. Imagine what open graph and schema can do for feeding Google information on creating deeper relationships. Couldn’t an expert (ala authorship) feed trust in a certain product? Couldn’t structured data improve Google’s trust of a page? Couldn’t Google start to figure out easier the intent of certain searches, and provide more relevant results based on your personalization and those relationships?
What if it could get to the point where I could simply Google the term “jaguar.” Google could know I’m a guitarist, I like Fender guitars, and I’m a fan of Nirvana (hell – it’s a lot less invasive than the data Target already has on me). Google could serve me pages on the Fender Jaguar guitar, the same guitar Kurt Cobain played. Now think about how you could get your clients in front of search results based on their relationships with your prospective searchers’ needs. Yup – exciting stuff.
Google is just getting started
An entity is an entity. Do this for your clients as well. The entries in Freebase ask for a lot of information that could very well influence your content production for the next year. Make your content and relationships on the web match your entries. At Matt Cutts’ keynote at Pubcon, he mentioned how they’re just scratching the surface on authorship. But I think authorship is just scratching the surface on semantic search. I think the big picture won’t manifest for another few years – but, no time like the present to start optimizing for relationships. At Greenlane, we’re pushing all our chips in on some huge changes this year and trying to get our clients positioned ASAP.
On a side note, I have a pretty interesting test brewing with entities, so watch this spot.





